Real-time Deep Learning.
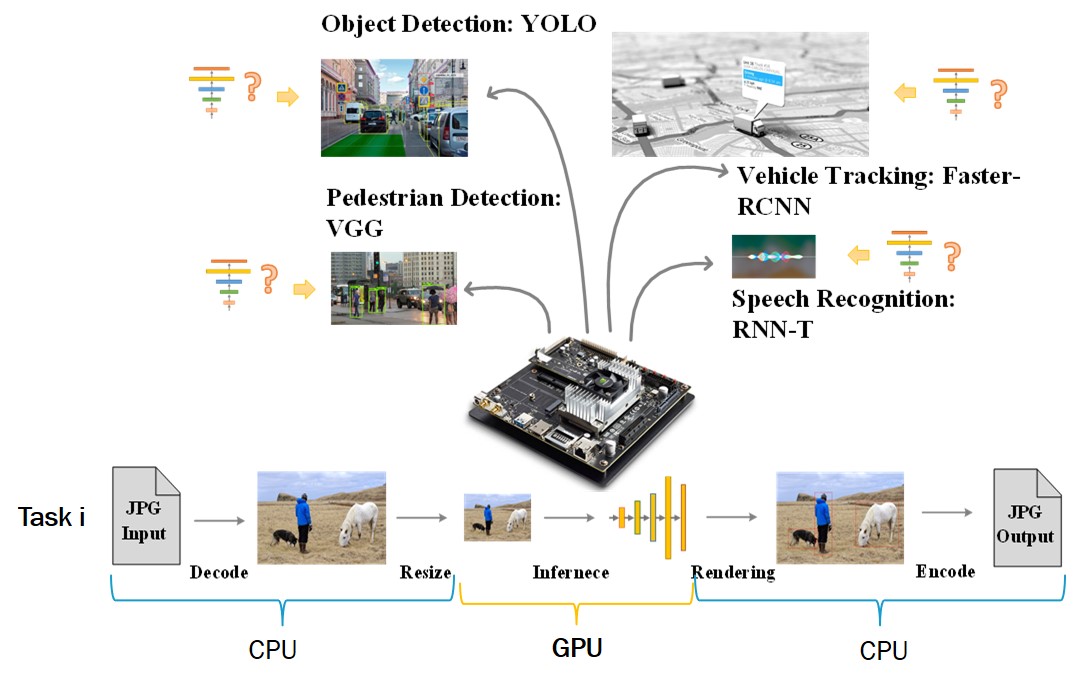
Recent years have witnessed an emerging class of real-time deep learning (DL) applications, e.g., autonomous driving,
in which resource-constrained edge platforms need to execute a set of mixed deep learning algorithms concurrently.
Such an application paradigm poses major challenges due to the huge compute workload of deep neural network models,
diverse performance requirements of different tasks, and the lack of real-time support from existing DL frameworks
(e.g., PyTorch, TensorFlow).
In this project, we will explore the execution performance of deep learning tasks and develop key Edge AI
techniques to support real-time deep learning on resource-constrained edge platforms,
including real-time DL task scheduling, DL task packing, multi-level model scaling.
In addition, we will study how to systematically exploit the latency-accuracy trade-off for multiple
DNNs to improve the runtime performance of real-time deep learning tasks under diverse user requirements.
Edge AutoML.
With the fast development of Internet of Things (IoT), large-scale of data are generated on edge devices,
which leads to the trend for deploying Deep Neural Network (DNN) on edge devices for data processing due to its overwhelming success in many data-driven applications.
However, low compute power and low battery capacity make it difficult for the edge device to afford the huge compute overhead of most state-of-the-art DNN models.
A direct approach is to offload the DNN compute workload to the cloud,
while the DNN model has to be executed locally under certain extreme conditions, such as poor communication channel condition.
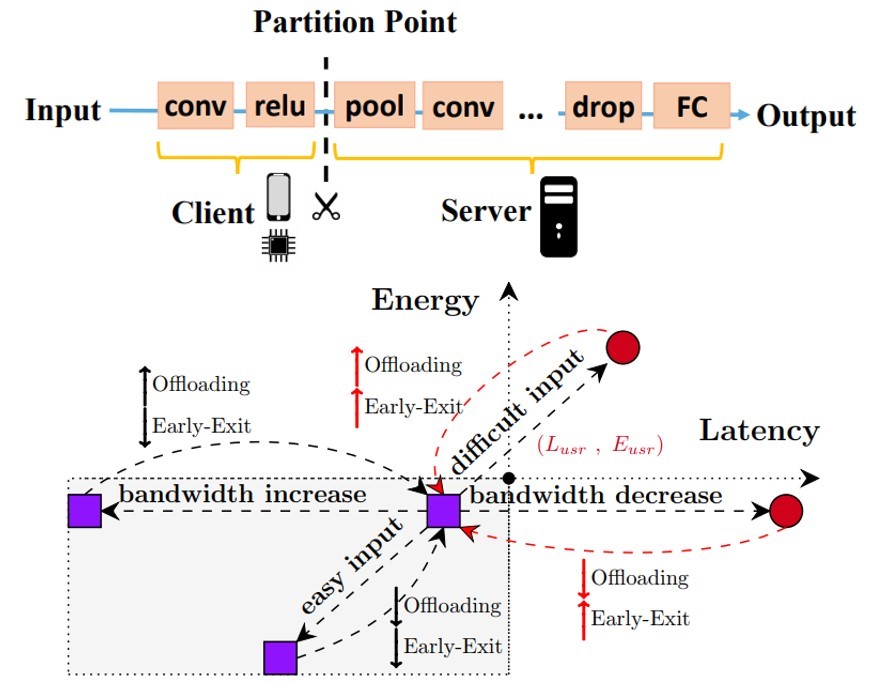
In this project, we apply the principle of AutoML to address the challenge of dynamic adaptation of model inference between the edge and cloud.
We propose a complete on-demand framework in consideration of all metrics for DNN inference and develop techniques combining workload offloading mechanism and dynamic progressive neural architecture.
As a result, the proposed framework can achieve a desirable trade-off between model accuracy,
edge device energy and end-to-end latency under significant runtime dynamics.